Useful Fundamentals of Computer Architecture for CG: Part 2
In a nutshell: Memory is virtualised by the operating system for protection and as a method of indirection to allow processes to act like they have more memory than is available in main memory. Since main memory is a precious resource, we often will have only the currently needed memory actually loaded into main memory, whilst less important data will be in secondary storage. Memory is divided up into “pages” of memory usually in 4kb sizes. We can add lots of pages together to provide the memory needed for a process. These can then be translated from a virtualised memory address into a physical address. We also have two types of data structures for different memory allocation. Small, fast memory with small scopes will be well suited to the “stack”, whilst larger and dynamic memory allocations are better suited to the “heap”.
In the previous post we began to shed some light on the two key parts of computer hardware that we are interested in for these blog posts- the CPU and memory. In the previous post we covered a bird’s eye view of the CPU and some important characteristics of modern CPU workflows. In this post, we will now go into more detail of memory. Remember that whenever we are writing code for a program, the data exists somewhere on the computer. That somewhere is in memory. So thinking about memory is really important to us.
Modern computers will be running several applications at one time. They are all fighting for the same memory. Many modern applications will require many gigabytes of memory. Unfortunately all of this won’t fit directly onto main memory. It isn’t a good idea to allow each individual application to have free rein of what parts of the memory it is allowed to have. This is instead managed by the operating system to schedule and structure memory allocation.
The operating system acknowledges that if we naively give every program exactly how much memory it asks for on main memory, we will run out of memory pretty quickly- it is an inevitability. This is where secondary memory storage becomes useful, such as hard drive or solid state disks; we can use it when main memory becomes exhausted.
Some requirements for memory management include the fact we need to be able to relocate memory. A process will be loaded into any location in main memory. The operating system will often need to be able to move a process around in memory for various reasons, so we cannot have a fixed “hard” memory allocation. Another important requirement is protection! The operating system will need to ensure a process cannot go off and access memory outside of its own allocated memory. The operating system cannot pre-screen this so it has to be achieved dynamically. One more requirement is the support for sharing, as some processes may use the same code or data.
Due to these events of relocating processes in memory, a program will use the “logical address” to access memory. Since addresses can change over time (due to the operating system moving and shifting memory around), logical addresses are better than using direct physical memory addresses. The logical address will store the memory offset such that when using this logical address, we can go off and find the real physical address in memory.
The operating system can also partition the available memory. Lets take a quick look at some potential ways to do this:
- Fixed partitioning is the simplest way to do this. We can take 8GB of memory and partition it into 8 bins of 1GB. This is certainly a good way to partition memory since we have safely have 8 different areas of memory for 8 different processes. However, what if one process only ever needs 512kb of memory? There’s a huge amount of this partition going to waste, imagine how many of these processes we could run in 1GB of memory! Additionally, if we have a processes that needs 1.2GB, it’ll have to take up 2 partitions (2GB). There is no way for other processes to borrow unused memory.

- Dynamic partitioning instead will create exactly how much memory the process needs. This is certainly better but if a process completes and there is a gap between two other processes in memory, this can be problematic and we get into a situation where we cumulatively have a lot of memory to spare, but because it is externally fragmented so much, we cannot bundle it together to use for a process. This leads to the computer slowing down prematurely, when there’s still lots of memory available, it is just fragmented. This could be overcome to an extent by compaction but this is costly and time consuming.



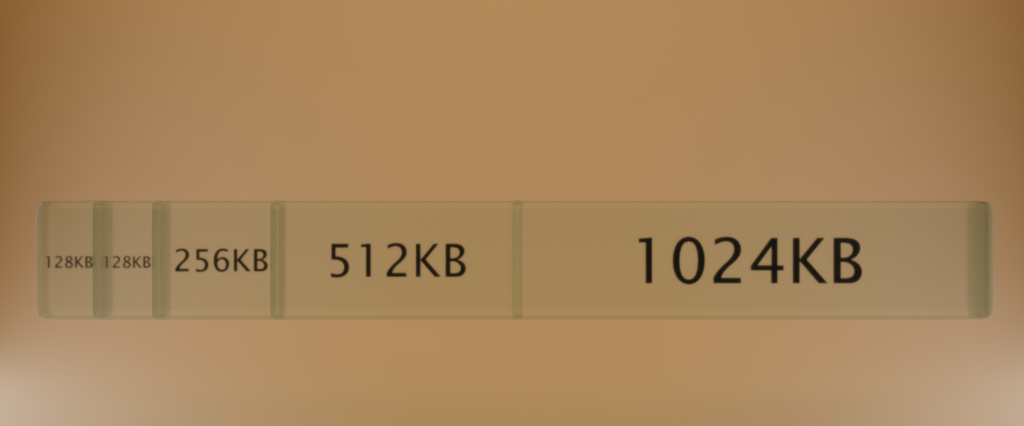
- Buddy System uses divisions of 2. So 2MB of memory would be split out into 128kb, 128kb, 256kb, 512kb etc. This helps avoid the issues of fixed partitioning but in practise isn’t always robust enough for multi purpose computers.
- Paging is the method that is used most often for modern memory management. This is where memory is broken into evenly sized “frames” or “pages” of information. If you remember in Secondary or High School Biology, we would go outdoors to a field of grass and divide up a patch of grass with quadrats. Each quadrat would contain “data”, meaning a sample of the plants/flowers inside the quadrat frame. Each quadrat would be the same size (likewise, memory pages are usually all 4kb). On the assumption that inspecting and reading from each quadrat takes the same amount of time, we can say it is analogous reading from RAM (Random Access Memory, the typical main memory). We can take advantage of this! The allocation of memory into these quadrat frames (or pages) does not need to be adjacent, since the act of reading random access memory has a fixed query time.
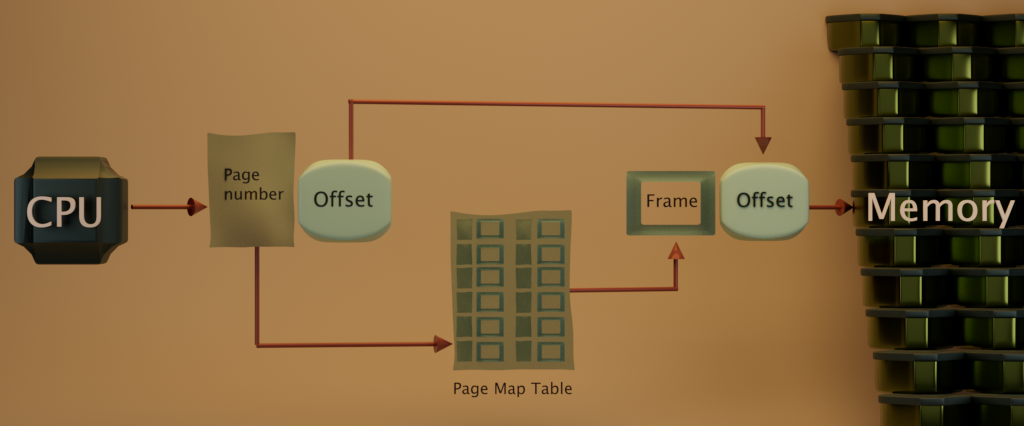
This makes relocation of memory easier to manage. The CPU needs to know how to look things up, so it uses a “page map table” which could be an array of page numbers. This is good because now we no longer have an external fragmentation anymore! We can keep growing the page map table easily, just append more frames (add more quadrats to the field) when required. Internal fragmentation will be reduced significantly due to the smaller sizes of these pages. This also means we will be protected from memory being accessed out of the scope of the process because by the nature of this system, no memory outside of the page map table can be accessed. Additionally, it makes sharing this resource easier too. One problem with paging however, is calculating the conversion between logical and the physical addresses of memory and the time it can take.
Virtual Memory
So it seems clear that paging is a good solution for allowing multiple processes to be able to gain access to the physical memory on a computer- it helps with protecting memory and avoids excessive external fragmentation due to the size of pages. We do pay a cost in translating between the logical address and physical addresses of memory though. Moving forwards, we can observe that a single process might not necessarily need all of its resources loaded into main memory at one time. For example in a video game if it plays the opening cinematic video sequence, title cards etc once the player progresses past the Start menu, there isn’t any need to keep that cinematic in main memory. The only way to access it again would be if we restarted the process! At this point, we could move the memory holding this information off to a secondary memory storage, such that we can use main memory for more pressing matters. By the way, just because we are moving data to secondary storage, this doesn’t mean it is gone. It can always be accessed and retrieved into main memory later. As a general rule, things that we need quickly and soon should be kept in main memory and things that we don’t need right now but may do later on, can be kept in secondary storage. It’s a bit like saying we need to keep kitchen knives inside the house, but something like a waffle maker, or slow cooker that may only be used for a few dishes every few months can safely be kept in the garage. We can think of the house as primary storage and the garage as secondary storage.
The Address Space
We are now aware of virtualised memory and using pages. But say we wanted to know how much memory a process uses, how can we track this? In turns out tracking memory utilisation in virtual memory is not a precise scenario. Let’s spend a bit of time exploring the key points on tracking/measuring memory usage, as it is really important. We know that most modern computers are 64-bit. But it used to be common to have 32-bit machines. 32 bits means 2^32, so we can represent values from 0 to 4,294,967,295. In total, that is 4GB of memory. The operating system also needs memory to carry out its own functions and allocations though. Anyway we will only focus on 64-bit machines now, since that is what is commonplace nowadays. 64-bits means 2^64 where we can represent values from 0 all the way to 18,446,744,073,709,551,616. Slightly more than 32-bit’s maximum number! Despite the fact most modern hardware is only using around 48-52 bits, we still use 64-bit (8 bytes) pointers, hence why it is called a 64-bit address space. Anyway, this is all to say that the address space is much bigger than the physical memory on a computer system. The address space is used to map physical memory as well as other resources. So if you are going to ask your operating system how much memory a processes is using, we will need to make sure we ask it properly. If we straight up ask what the size of the virtual address space in use by a process is, you are likely to get a very large and somewhat unreasonable number. Perhaps a game installed on your computer might say it is using 150GB of virtual memory, but you only have 16GB of physical main memory? Well, that now makes sense with our knowledge of memory pages. Maybe only some of this memory is in main memory, and the rest is stored on secondary storage. So, we are able to solve this mystery but this still isn’t solving how we measure the actual physical memory being used. Main memory is a finite and precious resource after all, we want to check how much we are using.
The quantity we are looking for is called the “Resident Set Size” or RSS. This is the amount of the physical memory that the operating system has made available to the processes, by mapping it to the process’ address space. The operating system provides the ability to query the size of the current resident set size, or the maximum resident set size.
#include <sys/resource.h>
#include <unistd.h>
#include <mach/mach.h>
size_t get_current_rss() {
// Configure what we want to query
mach_task_basic_info info;
mach_msg_type_number_t count = MACH_TASK_BASIC_INFO_COUNT;
// Retrieve basic infomation about the process
kern_return_t result = task_info(mach_task_self(), MACH_TASK_BASIC_INFO, (task_info_t)&info, &count);
if (result != KERN_SUCCESS)
return 0;
return size_t(info.resident_size);
}
size_t get_peak_rss() {
rusage usage_data;
getrusage(RUSAGE_SELF, &usage_data);
// From "man getrusage"
// ru_maxrss the maximum resident set size utilzied (in bytes)
return size_t(usage_data.ru_maxrss);
}
// Megabyte is 2^20 bytes, so just bit shift 1 along
double bytes_to_megabytes(const size_t& size_in_bytes) {
return double(size_in_bytes) / double(1<<20);
}The resident set size can be a useful metric but it is imprecise. If we have a process that uses 8GB of resident set size, that is a useful figure to know. But it doesn’t tell when, during the process this has happened. We don’t know what function call triggered this. Instead, we probably will want to query the RSS after each step of key computation in a process. Whilst the resident set size will tell us the amount of physical memory that the operating system has made available to the process, the working set size is a subset of this, which is what is actually needed for the process to execute.
To speed up translations of virtual (logical) memory addresses into physical memory addresses, a translation look aside buffer (TLB) is used, which is a memory cache that stores recent translations of memory. So if we constantly are using the same pages of memory for operations, it will execute faster than if we need to keep translating to find new pages of memory.
What happens when main memory runs out? The operating system will start “stealing” pages and it favours stealing pages which is likely not going to be used for a while anyway. This isn’t a free pass to consume all your main memory by the way. Thrashing our memory reads is bad news, performance grinds to a halt as the computer spends a lot of time paging memory in and out. This is because we first need to take pages out of main memory, then store them onto secondary storage. We then need to recover pages from secondary storage back into main memory and repeat this until all the required pages of memory are in main memory. This constant IO operation causes the poor performance.
By adding this intermediate layer between physical memory address and memory access, we achieve a level of indirection which gives a program the illusion of “unlimited” memory. It means we can have multiple processes in play and they can execute like they really have all the memory they need, when in actuality they might only have a certain portion mapped to main memory, whilst the rest is mapped to secondary storage.

The Stack and The Heap
We now have covered an overview of the key components in a computer, the CPU and virtual memory, and how processes can appear to use more memory than is actually available on the the computer’s main memory. Recall that the address space refers to the range of memory addresses that can be accessed by a process (these are pages of memory being chained together and looked up via translation offsets to convert from logical addresses to physical addresses). In the remainder of this blog post, I want to talk about the difference between the stack, and the heap. These are two different types of memory.
Stack
The stack is usually characterised as “small and fast”. If we write something like
float vertex_position[3] = {0};
for (int i = 0; i < 3; ++i)
{
vertex_position[i] = rand(); // Fill in value
}This is a pretty standard fixed length array right? Yes that’s right but its also a type of memory allocation! It is an inexpensive one but it is an example of allocating memory on the stack. Great, we know how to allocate some memory onto it, but what the heck IS the stack? Well, it is a block of memory addresses associated to each individual thread in a process. Remember, a process is the main thing that has several threads of execution and each thread has its own block of memory addresses it can use. These are its own stacks. The main thread will have the main stack, and individual stacks exist for every other thread spawned by the process. Typically the size for these stacks are in MB. The call stack is a sequence of function calls made as part of the control flow of a program. So when we are inside a function, the function “exists” in a frame within the stack where all the memory used by the variables local to the function exist.
If we call a function, a new frame within the stack is made. In this new frame, there will be space reserved for all variables that the new function will need to use. The stack frame will be removed from the stack when the function elapses. The previous frame (before this new function was called) is now restored as the current. When we place too much on the stack, we create a stack overflow. This isn’t great. Potentially one thread may start accessing and writing over another thread’s stack space. Since threads are blind to each other, we can get some pretty undesirable results. Luckily ASLR (Address Space Layout Randomization) is a security feature here to save us from breaking everything when we accidentally write out of bounds. It works by randomly arranging the address space positions of key data components like the stack, heap and libraries. This is a security technique to avoid an intentional exploitation or memory corruption as one cannot reliably jump to particular areas of the code and data.
The stack doesn’t clean up after itself but since all its allocations fall out of scope automatically when a function is returned, it doesn’t matter that we overwrite the memory. Once a function is returned, all data/arrays will simply stop existing. This means we don’t need to worry about memory leaks. Since stack memory is quite small and compact, it leads to memory access being quite fast thanks to data locality.
Heap
float* vertices;
uint32_t num_vertices = 2048;
vertices = (float*)malloc(sizeof(float) * num_vertices);
vertices = {0}; // Quickly set all values to 0The heap is a data structure utilised whenever we create dynamic memory allocations. This means whenever we call a memory allocation function like mmap, VirtualAlloc, calloc (sets to zero) or malloc (both of these call mmap under-the-hood usually), it is grabbing memory from the “heap” of memory. What this means is that the operating system will map segments of the address space to available memory and makes it available to the process. System calls for this can be expensive and it cannot map exactly what you request, only in page sizes. These page sizes will be 4kb as standard but can also be 2MB, 1GB etc depending on the operating system’s support. The heap is used as an intermediate so that we don’t directly map pages ourselves. It is designed to make sure we don’t end up with an entire page of 4096 bytes when we just wanted to allocate 12 bytes. When allocating small blocks of memory, special buffers are used. So if we are calling malloc for something the size of 10 bytes, it will be stored in an area reserved for 10 byte allocations. This is true for most small sized allocations. Unfortunately the heap does have some drawbacks. Dynamic allocations can fail to provide the heap memory you request. When this happens, there is no default error handling which can cause vulnerabilities and unstable programs. Of course, when we allocate memory, if we forget to deallocate it when we are finished, we end up with leaked memory. Unlike the stack, heap-allocated memory does not automatically fall out of scope since its not defined by default how long we want the memory allocation to exist for. Whenever there is a heap-allocation, we must remember to deallocate the memory once we no longer need it.
The key thing here is not to think of the stack as a magical fast type of memory and the heap as a slow, big lump of another type of memory. They are fundamentally still exactly the same under the hood, remember that memory is being virtualised and mapped via pages/chunks. But it is useful to understand that the stack is limited, best suited for small data structures and the heap is better suited for larger lists/data structures.
That covers it for the second post in this series. We have covered modern memory systems in this post. Whilst this is just scratching the surface of this subject, hopefully it has given some useful insight in understanding how memory is managed by the the Operating System. With part 1 and part 2 covering the CPU and Memory, we are in a good place for the final blog post to start to bring this all together. See you in the next blog post!