Useful Fundamentals of Computer Architecture for CG: Part 1
In a nutshell: For writing code that performs well and is fast to execute, we should focus on writing in a way that plays well with the hardware of a computer. This means we are interested in making sure that the CPU is being fed a constant stream of instructions to execute and the data is close together (this makes it faster to read and execute). Going out of the CPU to fetch data from main memory is very slow, so anything we can do to make sure we align data such that it ends up in the CPU’s on-board reserves of memory (caches) will help us. Additionally, utilising a multi-threaded environment is crucial for improving performance.
This will be another series of blog posts where I note down some concepts related to Computer Graphics that I have found interesting to me, both professionally and in personal work. I will be discussing some basics in computer hardware and architecture. Whilst not directly related to the graphics side of things, I have found this subject is really important. Understanding some basics of what the heck the computer is doing under-the-hood can be really insightful when trying to write faster code.
Whilst I am absolutely not an expert on this subject, I do feel there is value in someone with a non-technical background explaining these concepts in a more casual way. My aim is that these blog posts will cover enough about the very basics of modern computer hardware to hopefully shed some light on how to think about this topic in the context of graphics/rendering. So, rather than seeing the computer hardware as a magical box, the aim is to have a bird’s eye view of what happens under-the-hood.
Firstly, to create some rendering/graphics related context, there are a lot of common routines we repeat often in path tracing. Here are just a few:
- We spend a lot of time evaluating ray paths of variable lengths
- We spend a lot of time needing to query ray-shape intersections.
- We spend a lot of time accessing and sampling texture maps.
I could go on but you get the idea right? Ultimately this boils down to one simple fact- We spend a lot of time needing to read data from some places in memory performing some arithmetic/logic operations and then write out new data somewhere, very often! In the simplest form, we can say that any program takes data in, does some transformations and returns data out. Everything we do is just transforming data. If we want to make rendering sound as boring as possible, we could describe rendering as reading in a file, doing some calculations on the information of the file, and transforming the data of the file into an output image. Whilst it sounds dull when described like that, this idea of boiling down the process to just lots of data transformations is really important when it comes to thinking about how to write fast code.
This is something I was not aware of some years ago. Before learning about these topics, I previously always assumed from my limited knowledge that the best way to write code was in a way that abstracts difficult things away, bundle up similar things together and match some sort of mental model of the real world. Also I always felt I should do little things like ++i instead of i += 1 to optimise my code. That would help! Then, as long as I used techniques like acceleration structures, mip mapping or object instancing, surely my hobby renderers or texture processing tools should be fast! Shock and horror, I did exactly this and my hobby renderer was about 100x slower than Arnold at rendering a simple scene. To an extent, what my previous knowledge informed me of was good, using algorithms guided by Big-O notation is useful for sure, and its not a bad idea to favour code readability over some slight performance gains. However the key thing I was missing is that I was visualising the end platform to be the software itself. I just assumed the software should be written for this ideal, perfect computer where I don’t have to worry about real physical constraints! It’s not a problem if my program runs slow now, in a few years, a CPU will come along and my code will just run faster- I don’t have to do anything! This is unfortunately not a real solution. For a long time now, CPU clock speeds have not really progressed. Instead, the gains are in multi-core, multi-threaded applications. Memory read speeds have also not really progressed much in the past 20 years. These are very real aspects of the hardware that clearly aren’t magically going away any time soon. Besides, by dismissing a slow program by saying “Oh well it’ll get faster once faster CPUs come along” isn’t exactly the best marketing slogan. So, I have realised that when performance is critical it is far, far more productive to write code that makes the most of the available hardware on modern computers. Often, it would seem that a linear search through a contiguous array that fits onto the L1 cache line will be far more performant than a search tree with a good Big-O. Overall, I have found having a good understanding of cache lines, memory allocation, memory padding, multi-threading and SIMD to be really instructive for writing well-performing code. For the remainder of these blog post, I hope I can share the starting points that made this all click with me in a casual, easy to understand manner.
Under The Hood (literally)
Let us recap the key parts of a computer before we go further. I recommend opening up a desktop computer and just looking at whats what, getting familiar with the key parts of a computer. Incase you don’t want to do that right now, here is a picture of my own desktop:

1) The CPU lives here. It is covered mostly by the heat sink and cooling elements in this picture. This is what we will focus on for this blog post. Typically the CPU is referred to as the “brain” of the computer. It has millions/billions of transistors using logic gates (AND, NAND etc).
2) Here is our main memory (RAM). We will go into more detail about main memory on the next blog post. For now though, let’s just say that main memory is here. Notice that the CPU and memory are physically separate parts of the computer. So if our instructions/variables all live in memory, somehow the CPU needs to access those instructions/variables. The bus is needed to transfer information from the memory all the way to the CPU. This is non-trivial by the way. Going out from CPU and fetching something from main memory is expensive! The physical distance between them, the wires needed are a bottleneck.
Typically most home computers nowadays have between 8-32GB of RAM. With RAM, each byte (8-bits) has an address on RAM, a number between 0-255. We can group bytes together to store larger and larger variables such as floats. If we put 4 bytes together, we can represent values between +/- 2.1 billion. Each byte still stores a value between 0-255 and needs an address. If you are familiar with pointers in C, you will know that the addresses are typically expressed in hexadecimal. These memory addresses are virtualised (we will cover this later).
float my_number = 16.0f;
float* ptr_to_my_number = &my_number;
printf("The address of 'my_number' is 0x%p \n", ptr_to_my_number);> The address of 'my_number' is 0x00000019DB8FFE40
3) The hard drive disk, or secondary storage is located here. Being quite far away from the CPU, we can guess that it’ll be even slower to read from a hard drive disk than from RAM. RAM is better suited for temporary storage that is accessed frequently, whilst the hard drive disk is more suited for permanent and long term storage. It is not uncommon to have terabyte sized hard drive disks, whilst memory is usually around 8-32GB GB.
CPU In More Detail
Now, back to the CPU. The CPU operates by being given instructions of what to compute. Instructions (provided from source code) are compiled into a machine language, which are fed as instructions for the CPU. To action these instructions, CPUs use cycles of “fetch-decode-execute”. This means a single cycle of execution consists of the CPU going “I will fetch the next instruction (or information) to execute, from memory (might be from the CPU caches or main memory). I will then decode the instruction and figure out which instruction from my instruction set I should execute, and finally execute the correct instruction”. This is repeated for the next instruction, and the next and so on. The decoded instruction could be a mov, add, mult, jump, etc. The CPU is doing a great job of this by the way- it is executing this cycle 1-3 billion times a second. Nice!
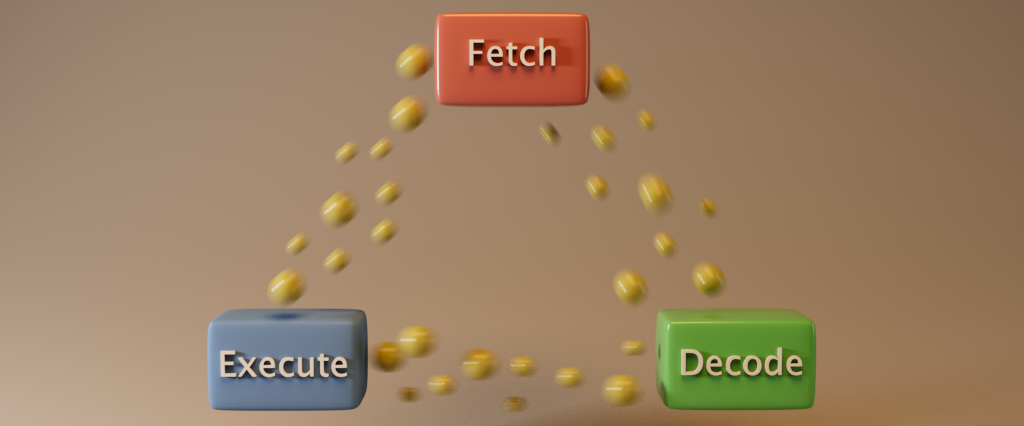
But why does it have this cycle of fetching and executing constantly? Why can’t it front-load all the fetching in one go? This is just how modern CPUs are designed, they do not have enough of their own memory to store entire programs, it would be too much to fit onto the CPU chip. So instead, the CPU will typically need to retrieve the next instruction in the cycle which will be cached somewhere in memory, store the instruction in a CPU register (basically an area where the CPU can execute an instruction on a locally stored value), figure out how many additional parameters are needed for that instruction to be completed (each instruction usually has 1, 2 or 3 parameters). It then will need to go back to main memory to retrieve these parameters and then finally it can run the code! This is what the CPU is doing at a really fast rate, fetching, decoding and executing instructions provided by a program!
Can you see the where the bottleneck might be here? It is the reading from memory. CPUs have registers which are very small amounts of memory just to perform operations and store results of those operations. On a 64-bit machine the registers will be 64-bits large. But, since these small amounts of memory are on-board the CPU, there’s almost no latency. This unfortunately is not the case when fetching from main memory which is super slow in comparison. It can take around 100 clock cycles to read an instruction from main memory. To speed things up a bit, CPUs have a small amount of memory that aren’t registers. These are small reserves of memory in the order of kilobytes and megabytes called the L1, L2 and L3 caches. The caches store data, instructions and TLBs (translation lookaside buffers, used to cache virtual and real memory addresses). Let’s just abstract this away to “cache” for now. Whilst not “free” to read from the CPU caches, they are significantly faster than reading instructions from main memory.
- L1 cache. The smallest and usually around 32kb of memory. This is the fastest to read from, requiring around 4 clock cycles.
- L2 cache. Broadly around 256kb of memory and typically requires 11 clock cycles needed to read from.
- L3 cache. 8MB of memory which is usually shared by each core in the CPU. Roughly 40 clock cycles.
- Main Memory. The slowest! This can take around 100 cycles to read from, a massive difference from the 4 clock cycles to read from L1 cache!

Hopefully this shows that we have very real hardware constraints which have huge implications on performance of the programs being executed on the CPU. Here are some key points which we will flesh out further:
- We will want to make sure we write code such that it is compact, well localised and fits onto CPU caches.
- We will want to have data structures/objects that are well packed, memory aligned and fit into cache lines. We want to avoid having arrays/containers where data structures are straddling cache lines
- Search/traversal for data structures that only touch data which is in the cache will be the fastest
Don’t worry if some (or all!) of these points aren’t making sense just yet. We will go into more detail!
Some More Info About CPU Instructions
Remember we mentioned that CPUs have registers? And that they decode and execute instructions? Let’s briefly have a look more in-depth at these aspects.
So the register is basically a container to hold the value you want to operate on. Like in a calculator where the main value you see on the LCD display is the “register”, and accumulates the result from various operations/instructions that we enter into the calculator. CPUs essentially have multiple of these containers, usually with simple names like A, B, r1, r2 etc. Instructions will usually reference these registers like “store r2 530” means store the value of register 2, into the memory address ‘530’.
We can’t just have any arbitrary instruction though. The CPU will come with a pre-determined set of instructions it understands. Unlike in our own programs where we can write our own custom functions to convert degrees to radians, write functions to intersect rays with triangles, the CPU cannot learn new instructions. It relies on pre-determined instructions. These pre-determined instructions are the “instruction set”. There are several types of architectures of instruction sets. the ISA for modern Intel x86 CPUs and the ISA for ARM CPUs are totally different. You cannot run native x86-friendly instructions on an ARM ISA. This is because they are speaking different “languages” with different instructions.
The two main instruction set architectures (ISA) are RISC and CISC. RISC uses Reduced Instruction Sets and CISC uses Complex Instruction sets. Modern x86 CPUs have very, very complex instruction sets. The opcodes will all have varying lengths, varying arguments and there are a lot of instructions. RISC, on the other hand (like ARM ISAs) are much simpler, more streamlined and fixed (same) length. There has been a back-and-forth between RISC and CISC ISAs and CPUs over the years. Let’s skip the history for today and just say that modern x86 CPUs initially generate CISC instructions and are then recompiling, slicing and dicing these instructions on-the-fly into RISC-like microcode which the CPU executes.
Increasing CPU speeds - Processes and Threads

Of course, there is a limit to how highly we can clock CPUs. We have the speed of light as a hard-fixed constant which we cannot go faster than. This is why most modern CPUs max out at around 3.2GHz. So to overcome this and ensure CPU speeds increase, the approach was to add multiple cores and “threads”, to run in parallel. These threads in a CPU are able to execute processes.
What is a process? It is an instance of a program execution. So if you have two instances of Maya open, whilst they are the same program, they are seen as two processes on the computer. This would contain the actual the code and any data/context associated with the process (all stored in memory, sometimes sequentially, but things such as system libraries will be in different areas of memory). The state of a process is also stored and monitored. We don’t need to know much more about this right now, but its important to know that the “process control block” or PCB is something maintained by the Operating System and it is responsible for paging memory and segmentation and holding process IDs (among other things!).
So that’s roughly what a process is, but what is a thread? Threads are basically “threads of execution”, so able to carry out sequences of operations. We can assign different threads of execution different tasks to help speed up execution. In the context of rendering, if we have a 1920x1080 image, we could split this up into 2 960x1080 images and ask two separate threads to carry out the ray tracing for each image. This is a super basic form of tiled rendering. It is worth noting that execution and resource ownership are separated into two distinct components. One, the process (resource ownership) and two, the thread (the execution component). While there will be only one process, the process itself may contain several threads of execution, each one only doing a component of the work required to get the overall task inside the process done. All components/threads will use the same resources and all threads have access to all the memory and all the files that the process itself owns.
So in a multi-threaded environment (which is every modern computer), we will have a process with a PCB that will be responsible for memory allocation, files and any linking needed. A thread of execution will have a TCB (thread control block) and have context of process registers, its own stack (for local variables, functions etc). We could use the analogy of a kitchen being used to prepare a family dinner. “Cooking a meal” would be the process. Perhaps one person chopping the vegetables could be one thread, one person cooking the rice is another thread, one person frying the meat could be another thread. They all share the same process, but each has their own threads of execution for their own tasks, probably their own allocated spaces to work in, which we can think of as their local stacks.
Whilst this slightly contrived analogy illustrates processes and threads, in actual programming context we would want a multi-threaded environment to do something whereby rather than having some sort of interactive program be executed serially and constantly stutter and stop whilst it carries out its linear execution, we could have one thread that is handling user input, one thread to log tasks, another thread to execute the instructions, etc. We might want some tasks to run constantly, and other tasks to run infrequently. Given that all modern computer CPUs have multiple cores and threads, we ideally want to writing programs in a way that lends itself well to utilising multiple threads of execution.
There are downsides to threads though. Let’s go over a few now. One of these is concurrency. Concurrency means a program can execute multiple tasks. But this doesn’t mean they happen in parallel, start and execute at the exact same times. One thread might be over-utilising the resource that other threads need. 2 threads using the same resource can be problematic especially when trying to schedule tasks. There is also an overhead to spawning threads, so having too many threads can slow down a program, rather than help it. We ideally want to have the “right” amount of threads.
So when we have a process using a multi-threaded environment, all the threads will have access and share the same resources that the process has. Threads will run as if they are separate programs, they are essentially “blind” to one another. This means they will run asynchronously, so we can have multiple tasks carried out in parallel.
Before we finish on this section about threads and execution, I want to quickly cover what the “Critical section” is. This is referring to a block of code that once in execution, has the expectation it will run uninterrupted until it is complete. If it is interrupted, this can result in asynchrony which may lead to corruption of data. The most common example is with “data races” where two threads might read a counter, check it isn’t above the max value, do some sort of computation and then increment the counter. Maybe we have a counter with a max value of 2048 and we have 2 threads. Both these threads access this counter value when it reads a value of 2047, but not at exactly the same time. Maybe thread 1 reads it first and begins reading and checking and is in the middle of executing its computation, but hasn’t updated the counter yet. Then, thread 2 comes along and also reads 2047, carries out its own reading, checking computation. Thread 1 finishes, increments the counter and moves onto something else. Thread 2 finishes afterwards and increments the counter. Suddenly, instead of maxing out at 2048, we hit 2049. Oh no! A little value going over doesn’t seem so bad, but imagine this was causing a memory overflow, data corruption or just leading to really unstable results. Just because it happens on one run of the program, doesn’t mean it always will happen. Since the OS manages resources in a non-deterministic fashion (it depends on what processes and applications are already open on the computer) we can never guarantee that threads 1 and 2 won’t try access the counter at the same time. Unless? Well, unless we introduce “atomic” operations. They are called atomic because they are “indivisible” and cannot be made any smaller. We would like it such that if thread 1 came along and read the counter, it has priority over all other threads and it should be allowed to continue its “critical section” before another thread is granted access to reading the counter. This solves the problem, but we don’t want to overly rely on this locking of information. If we have all our threads waiting on one thread to complete, it sort of defeats the point of multi-threading processors.
That covers it for part one. Let’s summarise what we have covered in this post. We took a look at the inside of a computer, noted where the CPU is, where the main memory is and noted there is physical distance between them, and that retrieving information from main memory can be costly. We then went a bit deeper into how the CPU tries to work around this bottleneck by having small reserves of its own memory. We will talk a bit more about cache lines later on. We then went over basics of CPU instruction set architectures such as RISC and CISC. This then led onto discussing how modern CPUs rely on multi-threading to achieve faster speeds. We defined the terms “processes” and “threads”, and then spoke about the issues we can have with a multi-threaded environment. So this has set us up well to explore other concepts in the next blog post. Hopefully this blog post has highlighted what is actually happening to execute code in programs you write, at least from the CPU’s perspective. Next time, we will talk about memory management and how an Operating Systems deals with memory. After that, we should be in a pretty knowledgable position to inform us about how to write our own programs to well performing. We want to be playing to the strengths and limitations of modern CPUs and memory. This is why we are taking the time to understand what the CPU and memory are doing under-the-hood (at least on a surface level).